
继ChatGPT成为全世界的焦点后,OpenAI再一次引爆了科技圈。
北京时间2月16日凌晨2点左右,美国OpenAI公司正式发布其首个文本-视频生成模型Sora。据报道,Sora能够根据文本提示创建详细的视频、扩展现有视频中的叙述以及从静态图像生成场景。
相较于文生图来说,文生视频难度更高,在数据质量、算力以及多融合技术的复杂性上都有诸多需要突破的关卡,所以一直以来文生视频的发展并不算顺利。
没想到OpenAI一出手就是王炸,Sora的实力可以说是藐视同行的存在。Sora 在日语中是“天空”的意思,引申含义还有“自由”,这不禁让我们想到马斯克“我们的目标是星辰大海”的豪情壮志。
OpenAI也强调“Sora是能够理解和模拟现实世界的模型的基础,我们相信这一功能将成为实现通用人工智能(AGI)的重要里程碑。”
同行们纷纷对Sora发出赞叹:马斯克「人类愿赌服输」,Runway联合创始人「game on」的感慨,360董事长周鸿祎作出“Sora意味着AGI实现将从10年缩短到1年”的预判,前阿里总裁贾扬清也评价道「非常牛」……
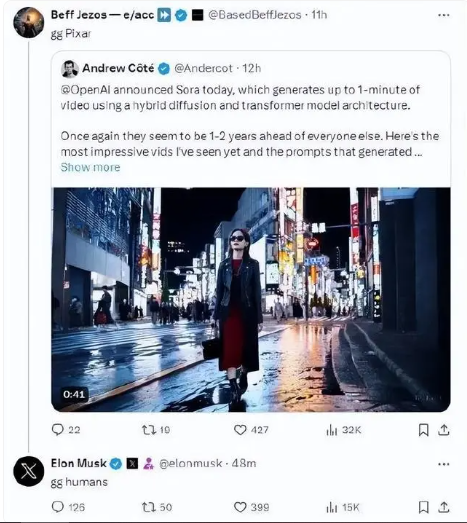
业界更是吹爆它“炸裂”“史诗级”“现实不存在了”……
那么,Sora为什么能独树一帜?Sora崛起将改变哪些行业?作为视频内容生产者,又该如何应对这场技术“大考”呢?
Sora碾压同行,OpenAI没有天花板
Sora模型是一个文生视频产品,通过简短或详细的提示词描述,或一张静态图片,Sora就能生成类似电影的逼真场景,涵盖多个角色、不同类型动作和背景细节等。
简单理解就是,只要输入一句话,AI就会根据你的描述,生成一段视频。
在Sora一口气发布的48个演示视频中,随便挑两个让大家感受一下Sora的实力。
比如,AI想象中的龙年春节,红旗招展人山人海。有不少儿童好奇抬头观望舞龙队伍,也有不少人掏出手机边跟边拍,海量人物角色各有各的行为。

再比如,一位时尚女性穿着黑色皮夹克、红色长裙和黑色靴子走在东京街道上,她戴着太阳镜,涂着红色口红,拎着黑色钱包,走路自信又随意。而刚下过雨的东京街道潮湿且反光,在彩色灯光的照射下形成镜面效果,细节超赞。

相比Runway、Pika等市面上现有的AI视频模型,Sora展示出了远超预期的能力,主要表现在这三点上。
第一,是视频长度的巨大提升,像Runway、Pika这些AI视频模型仅能生成不足10秒,而Sora的视频生成长度突破到了60秒。第二,是视频内容更加稳定。相比于其他AI视频模型镜头视角单一、内容高度失真,Sora的视频能实现单视频的多角度镜头切换,最大限度还原现实世界的真实场景,保持了合理的连贯性。
是深刻的语言理解能力,Sora能够深层次识别用户的指令,从而在生成的视频中呈现出丰富的表情和生动的情感,还表现出对物理世界部分规律的理解。
总之,Sora解决了过去AI视频被诟病的很多问题,它能形成更清晰的生成画面、更逼真的生成效果、更准确的理解能力、更顺畅的逻辑理解能力、更稳定和一致性的生成结果等等,目前,Sora已经成为最强的AI视频生成类模型。
而从技术层面来说,Sora之所以能够碾压同行,在于它采取了一个新的架构——Diffusion transformer模型。与Runway、Pika等主流AI视频聚焦于扩散模型不同,Sora这个模型融合了扩散模型与自回归模型的双重特性。
在这个新模型架构中,OpenAI沿用了此前大语言模型的思路,提出了一种用Patch(视觉补丁)作为视频数据来训练视频模型的方式。
简单理解,就是将视频和图片切成很多小块(这些小块就是Patch),OpenAI通过这种方式将视频压缩到一个低维空间,再用扩散模型模拟物理过程中的扩散现象来生成内容数据,生成的视频一开始看起来像静态噪音,然后通过多个步骤去除噪音,逐步转换视频。

不得不说,从文字(ChatGPT)到图片(DALL·E )再到视频(Sora),OpenAI团队就好像没有能力天花板一样。
Sora以碾压式的优势胜出后,资本端同时传来好消息。在完成最新交易后,OpenAI的估值已飙升至800亿美元以上。纽约时报报道也称,现在OpenAI的估值或达到约800亿美元。
“AI视频生成元年”来了
如果说2023年还是AI图文生成元年的话,那么今年OpenAI将推动行业进入AI视频生成元年。
事实上,在Sora发布前,探索AI视频模型的公司并不少,根据知名投资机构a16z此前的统计,截至2024年底,市场上共有21个公开的AI视频模型,包括大众熟知的Runway、Pika、Genmo以及Stable Video Diffusion等等。
以Runway为例,在2023年6月底完成由Google、Nvidia、Salesforce参与的C轮融资后,估值超过15亿美元。

但在Sora发布前,几乎所有的 AI 视频生成公司都陷入了同质化竞争,他们希望AI应用率先垂直落地到影视和广告场景,所以过多关注更高画质、更高成功率、更低成本,并且他们将能生成15秒视频作为一个里程碑。而Sora将眼光看向了更大时长的世界模型,这也是Sora成功的秘诀。
在OpenAI公布的Sora技术报告里谈道:“我们相信Sora今天展现出来的能力,证明了视频模型的持续扩展(Scaling)是开发物理和数字世界(包含了生活在其中的物体、动物和人)模拟器的一条有希望的路。”
换言之,OpenAI更愿意把Sora 视为理解和模拟现实世界的模型基础,而不是AI应用落地的场景。这意味着,相比其他玩家,OpenAI的思维永远更进一步。
面对Sora的降维打击,AI视频领域的创业者纷纷开启了追赶模式。比如Runway已经做好了“Game On”的准备;Pika创始人郭文景一样,开始筹备对标Sora的新产品……
而几乎是同一天,谷歌也发布了自家的最新大模型 Gemini 1.5。据介绍,Gemini 1.5的上下文窗口高达100万个tokens,可以一次处理大量的信息——如1小时的视频、11小时的音频、3万多行的代码等。
谷歌称,Gemini 1.5 Pro性能水平与谷歌迄今为止最大的模型1.0 Ultra 类似,并引入了长上下文理解方面的突破性实验特征,性能、文本长度均超越了GPT-4 Turbo。

Meta也不甘示弱,在近日公布了一种视频联合嵌入预测架构技术V-JEPA。据报道,这是一种通过观看视频教会机器理解和模拟物理世界的方法,V-JEPA可以通过自己观看视频来学习,而不需要人类监督,也不需要对视频数据集进行标记,甚至根据一张静止图片来生成一个动态的视频。
与其他模型相比,V-JEPA的灵活性使其在训练和样本效率上实现了1.5到6倍的提升。跑分方面,V-JEPA在Kinetics-400达到了82.0%的准确率,高于同行。

目前来看,国际上头部科技巨头基本已入局,大致可以分为“科技巨头+创业派+专业派”的组合,科技巨头以谷歌、Meta为代表,专业派以Adobe此类面向专业级用户的老牌软件巨头为代表,创业派以Runway、Pika为代表。
而国内目前的竞争格局还尚不清晰,目前大厂正在积极押注视频生成,比如字节跳动的文生视频模型MagicVideo-V2、阿达摩院的Zeroscope等。只能说,国内大厂也很忙,大语言模型大战才刚打响不久,现在又开始准备卷下一场战役。
但AI视频生成确实是一个颇具前景的创业赛道。目前来看,Midjourney估值100亿美元,Stability AI估值40亿美元,Runway估值15亿美元,就连成立时间不足一年的新贵Pika的估值已经达到2.5亿美元。
视频内容生产者慌不慌?
那么Sora的崛起,会影响哪些行业呢?
首当其冲的是传统影视行业。不少导演都说,影视行业“要变天了”。毕竟Sora能够生成长达60秒的视频,包括精细复杂的场景、生动的角色表情以及复杂的镜头运动。
而以往需要大量时间和资源来制作的特效和场景,现在可能只需要输入一些文字描述,Sora就能够自动生成这些高质量画面,这能够大大减少影视制作的预算,从前大几百万的影视制作现在或许只要十分之一,同时也能够代替一些不重要的职位,比如群演、灯光布置。
与此同时,还会有一个趋势,就是影视作品的门槛会急剧降低。对于一个年轻人来说,只要他脑海里有一个好故事,就能够依靠AI视频技术低成本创作出来。
其次,广告行业也能够被颠覆掉,特别是一些汽车广告、美食广告、旅游景点的广告,这些并不需要复杂情节的广告作品很容易被AI替代掉。
再者,短视频行业也会受到不小的冲击,由于Sora可以生成60秒的视频,会降低每一个普通人创作视频的门槛,对于抖音乃至TikTok来说,都会出现不少生成视频的内容。

最后是游戏开发和新闻媒体行业。AI可以辅助创造更加复杂和真实的视觉效果,这使得游戏开发者能够更快速、更高效地创建游戏内容和场景,同时也可以减少制作成本。
新闻行业中,Sora可以帮助快速生成新闻报道中所需的视频素材,尤其是在紧急情况下的现场报道。
当行业纷纷为Sora叫好的同时,万千视频生产者心里也难免复杂,Sora如此强大,科技已经如此恐怖,人类还能做什么?
不少网友直呼,工作要丢了,我该怎么办?
从内容创作者的角度来说,Sora带来的影响也需要辩证看待。
首先看悲观的方面,秉承着“万物不为我所有,万物为我所用”的原则,Sora能够代替人类完成一些简单、重复、追赶时效的工作。比如追逐热点和比拼速度的能力,人类创作者无论怎么努力也比不过AI。因此,可以预料到,未来“抓热点”性质的视频内容将会严重过剩,一部分内容方将被淘汰出局。
其次看积极的方面,Sora不具备创作者所必需的“灵魂”,不能胜任需要高度逻辑分析能力的深度解读,不能完全取代人类的专业技能和创造力。
所以优质的创作者完全可以与AI达成分工,AI负责信息与材料的收集(即重复劳动),而自己负责专业性的输出。
另外,Sora的实用价值还值得怀疑,它依然有不小的问题,比如它可能难以准确模拟复杂场景的物理原理;可能无法理解因果关系;还可能混淆提示的空间细节;可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹等。
其实,在AI 发展的数年沉浮之中,有关AI替代人类的种种争论从未停止,但“变”是常态,“不变”才不正常。
借用马斯克的一句话,“悲观毫无意义,我宁愿乐观”。生成视频的时代已经到来,与其担惊受怕地度过,不如抓紧人类手中的舵,投身这个AI新浪潮。